How The Brain Learns Foreign Languages
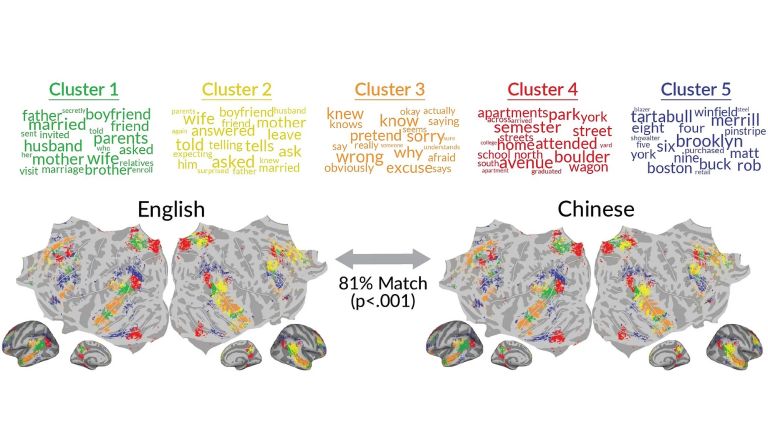
When our brain is learning a foreign language, it saves the new words and contexts in the same region where it originally saved the corresponding word in our native language. However, if you take a closer look at the areas of the brain and the individual words, you'll notice subtle differences between a foreign language and the native language. These shifts are very similar across the different individuals in the language combination under study, who are native speakers of Chinese with English as a foreign language. These are the key findings of a study conducted by the Chair of Language and Communication in Biological and Artificial Systems at TU Berlin in collaboration with researchers from the University of California, Berkeley, and which has now been published in PNAS. The head of the chair is Professor Dr. Fatma Deniz, vice president for digitalization and sustainability and incoming president of TU Berlin. The findings fundamentally expand our understanding of how humans learn languages and bring together two seemingly contradictory theories into a new model.
Published: 25.03.2026
These are two theories that suggest how newly learned language is anchored in the brain. Is the new term stored in the same part of the brain as it was in the native language? Or does it go in another region?
Neuroscientific studies on language learning contradictory
"Both hypotheses were supported in the past with experimental findings," says Deniz. "We thought it likely that the truth would be a little bit of both concepts." To test this new idea, Deniz and her team carried out intensive tests on six people in a brain scanner using Magnetic resonance imaging (MRT) at the University of California, Berkeley. All the test subjects were native speakers of Chinese and learned English as a second language. During the MRI brain scan, they spent several hours reading various stories in both Chinese and English in which people recounted their personal experiences on a wide range of topics. For every word they read, the researchers were able to use the MRI data to identify which region of the brain received a particularly strong blood flow while the word was being read. It is a plausible conclusion that this was the part of the brain that the word was stored in.
Magnetic resonance imaging
Magnetic resonance imaging scanner
A device used by medical professionals for magnetic resonance imaging (MRI). MRI is an imaging technique used to diagnose malformations in various tissues or organs of the body. This method is particularly effective for imaging parts of the body that contain a lot of water. Patients are placed in a tube (scanner) and exposed to a strong magnetic field. However, they are not exposed to X-rays or other forms of ionizing radiation.
Semantic representations: which words often come together?
The researchers from Berlin and Berkeley took a systematic approach to closely examine how language is processed in the brain when reading. First, they divided the brain into volumetric pixels, known as voxels – or in other words, small spatial regions. They then categorized the words from the stories into thematic groups using AI language models (the best-known of which is ChatGPT, though other language models were used in this case). These "semantic representations" focus on which words are used together in close proximity and with what probability. "We need to perform very complex statistical analyses here in order to arrive at meaningful results," explains Deniz.
Same same, but different
The experiments showed that different thematic areas are processed with a certain probability in each voxel. For example, words that express spatial orientation, such as south, front, and apartment, are processed with an 80% probability in one voxel. However, that same voxel also processes entirely different topics; for example, there is a 20% probability that it will contain words relating to vehicles. "One thing we discovered was that these umbrella topics and the corresponding probability for each voxel remain the same, regardless of whether the person was reading a Chinese or an English text. So each voxel is 'interested,' so to speak, in the same things, regardless of what language is being used," she continues. "But when we take a closer look at which words trigger which voxel, we notice shifts within these otherwise consistent umbrella topics." For example, in Chinese, a voxel associated with spatial orientation primarily processes words related to relationships, such as "arrive" and "together." However, when reading an English text, this shifts to words that have more to do with directions and numbers, such as "north" or "seven (kilometers)."
Clever way to verify results
Despite the small sample size of six participants, the researchers are very confident that their findings are valid. This is due to the specific design of their experiment, in which models were trained using machine learning to reproduce the measurement results for the participants. The model parameters were initially adjusted using only four participants. These models were then able to accurately predict both the distribution of voxels across topics and the shifts described above in the other two participants.
Previous experiments incorporated into study
Another finding also supports the study's results: In a previous experiment, Fatma Deniz's research group had scanned the brains of participants while they read the same texts in English – though in that study, the participants were native English speakers, and the focus was on the difference between reading and listening to texts. "We observed similar semantic shifts in the English texts between the scans of native English speakers and those of the participants in the new experiment, who had learned English as a second language. This implies that these shifts do not constitute a specific difference between English and Chinese, but may instead represent a difference between a native language and a foreign language."
Experiments with further language combinations planned
The researchers from Germany and the US now plan to expand their experiments to other languages, including those that have more similarities than Chinese and English, such as Italian and Spanish. They also plan to reverse the experiment in the future; that is, to work with participants whose native language is English and whose first foreign language is Chinese. "With what we consider to be a successful synthesis of the two opposing hypotheses in neuroscientific language research, we have made significant progress in understanding how language learning works," Deniz says. These findings could also potentially aid in the rehabilitation of aphasia patients who, after suffering damage to certain regions of their brain, are no longer able to properly express or understand spoken or written language. "In general, our basic research provides an important foundation for anyone who wants to improve the understanding and learning of foreign languages and, by extension, human communication."
